
【Java Web入門 #10】標準タグライブラリ(JSTL)の利用(2)|Functionsタグライブラリ
2025.02.14
前回の記事(Java Web入門 #9)では、JSPの標準タグライブラリの導入と、coreライブラリの各タグの利用方法について説明しました。当記事では、文字列を扱うための関数として準備されているFunctionsタグライブラリについて、各タグの利用方法を中心に説明します。
◆Java Web入門の過去記事はこちら
◆Java入門 記事一覧はこちら
目次
Functionsタグライブラリの利用
Functionsタグライブラリの概要
JSTLのFunctionsタグライブラリは、JSTL1.1で追加されたタグライブラリです。主に文字列の判定や操作のための機能が準備されており、他のタグとは異なり<>で囲むのではなく、EL式の中で利用されます。
特に文字列の判定機能は、coreライブラリの<c:if>タグや<c:when>タグと組み合わせて利用することで、スクリプトレットを利用せずに変数の値によって分岐などが可能となり、JSPコードの簡素化につなげることが可能となっています。
taglibディレクティブ
Functionsタグライブラリを利用するには、coreタグライブラリの利用時と同様、JSPに taglib ディレクティブの記述が必要です。Functionsタグライブラリのプレフィクスには通例として「fn」が利用されます。(当記事でもプレフィクスを「fn」として説明します)
(JSTL3.0の場合)
<%@ taglib uri="jakarta.tags.functions" prefix="fn" %>
(JSTL2.0以前の場合)
<%@ taglib uri="http://java.sun.com/jsp/jstl/functions" prefix="fn" %>
1つのJSP内で複数のタグライブラリを利用する場合は、対象のタグライブラリの taglib ディレクティブを全て記述します。
※各タグライブラリのuriについては、前回の記事(利用手順とcoreライブラリ 4.1 書式)をご参照ください。
<%@ taglib uri="jakarta.tags.core" prefix="c" %>
<%@ taglib uri="jakarta.tags.functions" prefix="fn" %>各タグの仕様
文字列の判定
| fn:contains( ) | 対象の文字列内に、指定した文字列が含まれているかどうかを返す (大文字と小文字は区別される) |
| fn:containsIgnoreCase( ) | 対象の文字列内に、指定した文字列が含まれているかどうかを返す (大文字と小文字を区別しない) |
| fn:startsWith( ) | 対象の文字列が、指定した文字列から始まるかどうかを返す |
| fn:endsWith( ) | 対象の文字列が、指定した文字列で終わるかどうかを返す |
| fn:indexOf( ) | 対象の文字列内において、指定した文字列が含まれている位置を返す |
参考:Jakarta Standard Tag Library 3.0 Tagdoc(公式サイト・英語)
fn:contains( )
fn:contains タグは、検査対象の文字列の中に、指定した文字列が含まれているかどうかを判定します。大文字と小文字は区別して判定されます。
書式:
${ fn:contains( String【検査対象の文字列】, String【含まれる文字列】) }
戻り値:
boolean 指定した文字列を含む場合はtrue/含まない場合はfalse
<%-- 検査用の文字列変数 --%>
<c:set var="str" value="abcde" />
<%-- true: strには'bc'が含まれている --%>
${fn:contains(str, 'bc')}
<%-- false: strに大文字'AB'は含まれていない --%>
${fn:contains(str, 'AB')}
<%-- false: strに連続した文字列'ac'は含まれていない--%>
${fn:contains(str, 'ac')} fn:containsIgnoreCase( )
fn:containsIgnoreCase タグは、検査対象の文字列の中に、指定した文字列が含まれているかどうかを判定します。こちらは大文字と小文字を区別せずに判定します。例えば「AB」を含むかどうかを判定する場合、検査対象の文字列の中に「AB」「ab」「Ab」「aB」のいずれかが含まれていれば true が返されます。
書式:
${ fn:containsIgnoreCase( String【検査対象の文字列】, String【含まれる文字列】) }
戻り値:
boolean 指定した文字列を含む場合はtrue/含まない場合はfalse
<%-- 検査用の文字列変数 --%>
<c:set var="str" value="abcde" />
<%-- true: strには'bc'が含まれている --%>
${fn:contains(str, 'bc')}
<%-- true: strには小文字の'ab'が含まれている --%>
${fn:contains(str, 'AB')} fn:startsWith( )
fn:startsWith タグは、検査対象の文字列が指定した文字列で始まるかどうかを判定します。大文字と小文字は区別して判定されます。また、先頭の文字列としてnullまたは空文字を指定した場合は、常にtrueとなります。
書式:
${ fn:startsWith( String【検査対象の文字列】, String【先頭の文字列】) }
戻り値:
boolean 指定した文字列で始まる場合はtrue/始まらない場合はfalse
<%-- 検査用の文字列変数 --%>
<c:set var="str" value="abcde" />
<%-- true: strは'a'で始まる --%>
${fn:startsWith(str, 'a')}
<%-- false: strは大文字'A'で始まっていない --%>
${fn:startsWith(str, 'A')}
<%-- true: 空文字を指定した場合は常にtrue --%>
${fn:startsWith(str, '')} fn:endsWith( )
fn:endsWithタグは、検査対象の文字列が指定した文字列で終わるかどうかを判定します。大文字と小文字は区別して判定されます。また、末尾の文字列としてnullまたは空文字を指定した場合は、常にtrueとなります。
書式:
${ fn:endsWith( String【検査対象の文字列】, String【末尾の文字列】) }
戻り値:
boolean 指定した文字列で終わる場合はtrue/終わらない場合はfalse
<%-- 検査用の文字列変数 --%>
<c:set var="str" value="abcde" />
<%-- true: strは'e'で終わる --%>
${fn:endsWith(str, 'e')}
<%-- false: strは大文字'E'で終わっていない --%>
${fn:endsWith(str, 'E')}
<%-- true: 空文字を指定した場合は常にtrue --%>
${fn:endsWith(str, '')} fn:indexOf( )
fn:indexOf タグは、検査対象の文字列の中に、指定した文字列が含まれている位置(インデックス)を返します。大文字と小文字は区別して判定されます。
指定した文字列が複数回含まれている場合は、先頭から見て最初に一致した位置が返されます。また、指定した文字列が含まれていない場合は-1が返されます。
書式:
${ fn:indexOf( String【検査対象の文字列】, String【含まれる文字列】) }
戻り値:
int 指定した文字列が最初に見つかったインデックス(0~)。見つからない場合は-1。
<%-- 検査用の文字列変数 --%>
<c:set var="str" value="abcdeabc" />
<%-- 0: str内に最初に'a'が現れる位置 --%>
${fn:indexOf(str, 'a')}
<%-- 2: 複数文字での一致の場合は、先頭の文字(c)の一致した位置 --%>
${fn:indexOf(str, 'cde')}
<%-- -1: 見つからない場合は-1 --%>
${fn:indexOf(str, 'efg')}
これらの文字列の判定は、coreタグライブラリの<c:if>タグや<c:choose>タグ+<c:when>タグなどを利用する際に、判定条件として利用できます。以下は、<c:if>タグや<c:when>タグの test 属性に対して、これらの判定結果を利用する例です。
<%@ page contentType="text/html; charset=UTF-8" %>
<%@ taglib uri="jakarta.tags.core" prefix="c" %>
<%@ taglib uri="jakarta.tags.functions" prefix="fn" %>
<c:set var="str" value="abcde"/>
<html>
<head>
<meta charset="UTF-8">
<titleFunctionsタグライブラリの利用</title>
</head>
<body>
<p>
<c:choose>
<c:when test="${fn:contains(str, 'cde')}">
${str}は'cde'を含んでいます。
出現位置は${fn.indexOf(str, 'cde') + 1}番目の文字です。
</c:when>
<c:otherwise>
${str}は'cde'を含んでいませんでした。
</c:otherwise>
</c:choose>
</p>
<p>
<c:if test="${fn:startsWith(str, 'a')}" >${str}の最初の文字はaです。</c:if>
</p>
<p>
<c:if test="${fn:endsWith(str, 'e')}" >${str}の最後の文字はeです。</c:if>
</p>
</body>
</html>文字列の切り出し
| fn:substring( ) | 対象の文字列の指定した開始位置から終了位置までの部分を返す |
| fn:substringAfter( ) | 対象の文字列の指定した文字列より後ろの部分を返す |
| fn:substringBefore( ) | 対象の文字列の指定した文字列より前の部分を返す |
参考:Jakarta Standard Tag Library 3.0 Tagdoc(公式サイト・英語)
fn:substring( )
fn:substring タグは、編集対象の文字列内から指定された範囲を切り出した文字列を返します。
切り出す範囲は引数で指定し、指定された開始位置から、終了位置の前の文字までが切り出されます。開始位置に負の値が渡された場合は先頭から、終了位置に負の値が渡された場合は末尾までの文字列が返されます。
書式:
${ fn:substring( String【編集対象の文字列】, int【開始位置】, int【終了位置】) }
戻り値:
String 編集対象の文字列から、「開始位置~終了位置の1つ前」までを切り出した文字列
<%-- 編集用の文字列変数 --%>
<c:set var="str" value="abcde" />
<%-- 'abc': 0番目から3番目の前まで --%>
${fn:substring(str, 0, 3)}
<%-- 'b': 1番目から2番目の前まで --%>
${fn:substring(str, 1, 2)}
<%-- 'ab': 先頭から2番目の前まで --%>
${fn:substring(str, -1, 2)}
<%-- 'bcde': 1番目から末尾まで --%>
${fn:substring(str, 1, -1)} fn:substringAfter( )
fn:substringAfter タグは、編集対象の文字列内から指定した文字列より後ろの部分を切り出した文字列を返します。
指定した文字列が含まれていなかった場合は空文字が返されます。但し、nullや空文字を指定した場合は、編集対象の文字列がそのまま返されます。また、指定した文字列が複数回含まれている場合は、先頭から見て最初に一致した箇所から後ろの文字列が返されます。
書式:
${ fn:substringAfter( String【編集対象の文字列】, String【含まれる文字列】) }
戻り値:
String 最初に見つかった検査文字列以降の文字列。見つからない場合は空文字。
<%-- 編集用の文字列変数 --%>
<c:set var="str" value="abcdeabc" />
<%-- 'eabc': 'd'より後ろの文字列 --%>
${fn:substringAfter(str, 'd')}
<%-- 'deabc': 最初の'bc'より後ろの文字列 --%>
${fn:substringAfter(str, 'bc')}
<%-- '': 指定した文字列が含まれてない --%>
${fn:substringAfter(str, 'xyz')}
<%-- 'abcdeabc': 空文字・nullを指定 --%>
${fn:substringAfter(str, '')}fn:substringBefore( )
fn:substringAfter タグは、編集対象の文字列内から指定した文字列より前の部分を切り出した文字列を返します。
指定した文字列が含まれていなかった場合や、nullや空文字を指定した場合は空文字が返されます。また、指定した文字列が複数回含まれている場合は、先頭から見て最初に一致した箇所より前の文字列が返されます。
書式:
${ fn:substringBefore( String【編集対象の文字列】, String【含まれる文字列】) }
戻り値:
String 最初に見つかった検査文字列より前の文字列。見つからない場合は空文字。
<%-- 編集用の文字列変数 --%>
<c:set var="str" value="abcdeabc" />
<%-- 'abc': 'd'より前の文字列 --%>
${fn:substringBefore(str, 'd')}
<%-- 'a': 最初の'bc'より前の文字列 --%>
${fn:substringBefore(str, 'bc')}
<%-- '': 指定した文字列が含まれてない --%>
${fn:substringBefore(str, 'xyz')}
<%-- '': 空文字・nullを指定 --%>
${fn:substringBefore(str, '')}
fn:substringAfter タグと fn:substringBefore タグは、特定の文字列(デリミタ)で連結された文字列を扱いたい場合などに利用できます。以下の例では「00:00」形式の時刻の文字列を「00時00分」に置き換えて表示しています。
<%@ page contentType="text/html; charset=UTF-8" %>
<%@ taglib uri="jakarta.tags.core" prefix="c" %>
<%@ taglib uri="jakarta.tags.functions" prefix="fn" %>
<c:set var="str" value="12:34"/>
<html>
<head>
<meta charset="UTF-8">
<title>Functionsタグライブラリの利用</title>
</head>
<body>
<p>
${fn:substringBefore(str, ':')}時${fn:substringAfter(str, ':')}分
</p>
</body>
</html>文字列の編集
| fn:trim( ) | 対象の文字列の前後の空白を取り除く |
| fn:toLowerCase( ) | 対象の文字列を全て小文字に変換する |
| fn:toUpperCase( ) | 対象の文字列を全て大文字に変換する |
| fn:replace( ) | 対象の文字列内の指定した文字列の部分を、別の文字列に置き換える |
| fn:escapeXml( ) | 対象の文字列内のXML特殊文字(<> & ' " )をエスケープする |
参考:Jakarta Standard Tag Library 3.0 Tagdoc(公式サイト・英語)
fn:trim( )
fn:trim タグは、文字列の前後にある空白(※)を除去した文字列を返します。
(※半角スペースおよび、Tabや改行コードなど)
文字列の先頭または末尾に連続して空白がある場合は、全て取り除かれます。日本語の全角スペースや、文字の途中にある空白は除去されません。
書式:
${ fn:trim( String【編集対象の文字列】) }
戻り値:
String 編集対象の文字列から前後の空白を取り除いた文字列
<%-- 'You are a quick learner!'が返される --%>
${fn:trim(' You are a quick learner! ')}fn:toLowerCase( )
fn:toLowerCase タグは、文字列を全て小文字にした文字列が返されます。英字のアルファベット以外にも、キリル文字(Я → я)やウムラウト付の文字(Ä → ä など)も変換されます。(但し、Webブラウザなどで正常に表示されるかどうかは利用しているコンピューターの環境に依存する場合があります)
日本語の小書き文字(「や」→「ゃ」など)や、全角カナと半角カナなどは変換対象にはなりません。
書式:
${ fn:toLowerCase( String【編集対象の文字列】) }
戻り値:
String 全て小文字に変換した文字列
<%-- 'hello world!'が返される --%>
${fn:toLowerCase('Hello world!')}fn:toUpperCase( )
fn:toLowerCase タグは、文字列を全て大文字にした文字列が返されます。変換対象は fn:toLowerCase タグと同じです。
書式:
${ fn:toUpperCase( String【編集対象の文字列】) }
戻り値:
String 編集対象の文字列を全て大文字に変換した文字列
<%-- 'HELLO WORLD!'が返される --%>
${fn:toUpperCase('Hello world!')}fn:replace( )
fn:replace タグは、編集対象の文字列の中にある、置換対象として指定した文字列の部分を、置換先として指定した文字列に置き換えた文字列を返します。置換対象の文字列の判定は、大文字と小文字を区別します。
複数箇所が置換元の文字列と一致する場合は、全て置き換えられます。また、置換対象として指定した文字列を含まない場合は、元の編集対象の文字列がそのまま返されます。
書式:
${ fn:replace( String【編集対象の文字列】, String【置換対象の文字列】, String【置換先文字列】) }
戻り値:
String 編集対象の文字列内の検査文字列を全て置換文字列に置き換えた文字列。
<%-- 'bcbcbc'が返される --%>
${fn:replace('abcabcabc', 'a', '')}
<%-- 'xbcxbcxbc'が返される --%>
${fn:replace('abcabcabc', 'a', 'x')}
<%-- ''(空文字)が返される --%>
${fn:replace('abcabcabc', 'abc', '')}
<%-- 'xxx'が返される --%>
${fn:replace('abcabcabc', 'abc', 'x')}
<%-- 'xyxyxy'が返される --%>
${fn:replace('abcabcabc', 'abc', 'xy')}
<%-- 'abcabcabc'がそのまま返される --%>
${fn:replace('abcabcabc', 'x', 'y')}fn:escapeXml( )
fn:escapeXmlタグは、編集対象の文字列の中にあるXML特殊文字をエスケープした文字列を返します。エスケープされるXML特殊文字列は「<」「>」「&」「 '」「 "」の5つです。
書式:
${ fn:escapeXml( String【編集対象の文字列】) }
戻り値:
String 編集対象の文字列内のXML特殊文字列(<>& ' " )をエスケープした文字列
<%-- XMLエスケープされた文字列が返される --%>
${fn:escapeXml('<>& \' " ')}
上記の内容を実際に出力したときのブラウザ上の表示と、出力されたHTMLソースは以下の通りです。
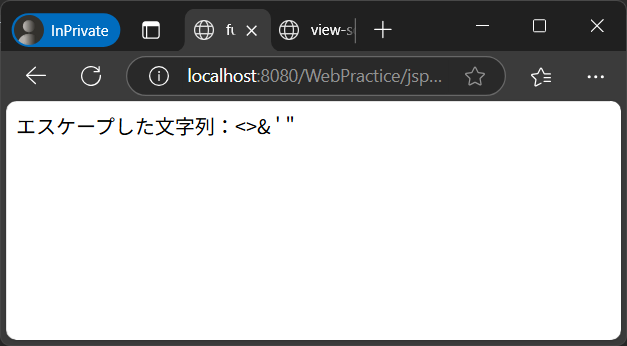
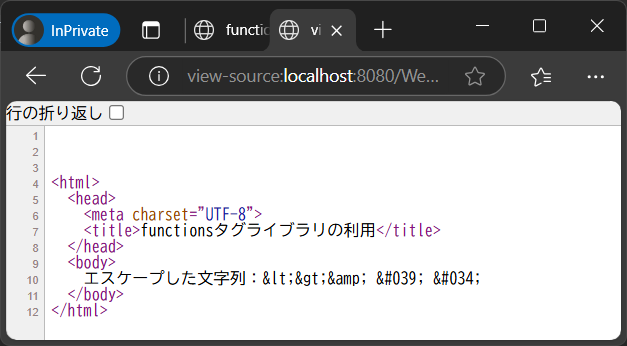
ただし、coreタグライブラリの<c:out>タグでこれらのXMLエスケープした文字列を出力する場合は、fn:escapeXMLを利用しなくてもエスケープされます。このため、これらの文字を含む可能性がある変数をHTML上に出力する場合は、<c:out>タグを利用することを推奨します。
<%-- XML特殊文字を含む変数の定義 --%>
<c:set var="xmlStr" value="<>&'\"" />
<%-- 以下はどちらもXML特殊文字がエスケープされて出力される --%>
<p>${fn:escapeXml(xmlStr)}</p>
<p><c:out value="${xmlStr}"/></p>配列・コレクションの利用
| fn:length( ) | 対象の文字列または配列、コレクションの長さ・要素数を返す |
| fn:join( ) | 配列内の文字列を、指定した文字列で連結する |
| fn:split( ) | 対象の文字列を指定した文字列で分割した配列を返す |
参考:Jakarta Standard Tag Library 3.0 Tagdoc(公式サイト・英語)
fn:length( )
fn:length タグは、文字列の長さ(文字数)、または配列・コレクションの要素数を返します。nullが引き渡された場合は0(ゼロ)を返します。
書式:
${ fn:length( Object【対象の文字列 または配列・コレクション】) }
戻り値:
int 文字列の長さ、または配列・コレクションの要素数
<%-- 文字列の場合は文字数を返す --%>
${fn:length('Hello, world!')}
<%-- 配列・コレクションの場合は要素数を返す --%>
<%
String[] strarr = {"a", "b", "c"};
pageContext.setAttribute("arr", strarr);
%>
${fn:length(arr)}fn:join( )
fn:join タグは、配列内の各文字列を指定した区切り文字で連結した文字列を返します。配列内の「要素」がnullまたは空文字であっても、1つの要素として連結されますが、nullの場合は「null」という文字列として出力されることに注意してください。
また、引き渡された「配列自体」がnullまたは空の配列・コレクションであった場合は空文字が返されます。
書式:
${ fn:join( String[]【連結対象の配列】, String【区切り文字列】) }
戻り値:
String 配列の全要素を連結文字列で連結した文字列
<%
String[] strarr = {"a", "b", null, "c", "", ""};
pageContext.setAttribute("arr", strarr);
pageContext.setAttribute("nul", null);
%>
<%-- 「a,b,null,c,,」が出力される -->
<p>${fn:join(arr, ',')}</p>
<%-- 空文字が出力される -->
<p>${fn:join(nul, ',')}</p>fn:split( )
fn:split タグは、区切り文字で連結されている文字列を、指定した区切り文字で分割した「文字列の配列」を返します。
指定した区切り文字が含まれていない場合(分割されなかった場合)や、区切り文字にnullや空文字を指定した場合は、元の文字列のみを要素に持つ(要素数1の)配列が返されます。また、分割対象として空文字またはnullを引き渡した場合は、空文字を1つだけ要素に持つ配列が返されます。
書式:
${ fn:join( String【分割対象の文字列】, String【区切り文字(列)】) }
戻り値:
String[] 分割対象の文字列をデリミタで分割した配列(空の要素を除く)
<%-- 要素数3の配列 {"a", "b", "c"} が返される --%>
${fn:split('a,b,c', ',')}
<%-- 要素数1の配列 {"a,b,c"} が返される --%>
${fn:split('a,b,c', '|')}
<%-- 要素数1の配列 {""} が返される --%>
${fn:split('', ',')}
fn:split タグを利用した分割では、分割した要素が空だった場合、配列の要素として加えられないことに注意してください。
例えば文字列 "a,b,,,c,d,,e" を "," で分割した場合、返される文字列の配列は {"a","b","c","d","e"} となります。{"a","b","","","c","d","","e"} となることを期待していた場合、予期せぬ動作となることがあります。
<%-- 配列 {"a", "b", "c", "d", "e"} が返される --%>
${fn:split('a,b,,,c,d,,e', ',')}
また、句切り文字として複数の文字列を指定した場合は、その文字列の中のいずれかの「文字」で分割されることにも注意してください。例えば区切り文字に "xyz"と指定した場合は、"x"、"y"、"z" が区切り文字とみなされます。
このため、区切り文字に同じ文字を複数個使っても、1個しか使わない場合と同じ動作となることにも注意が必要です。
<%-- 配列 {"A", "B", "C", "D", "E", "F"} が返される --%>
${fn:split('AxByCzDxyEyzF', 'xyz')}
<%-- 配列 {"京都", "区", "上野"} が返される --%>
${fn:split('東京都台東区東上野', '台東')}
<%-- 配列 {"京都", "上野"} が返される --%>
${fn:split('東京都台東区東上野', '台東区')}
<%-- 配列 {"A", "B", "C", "D", "E"} が返される --%>
${fn:split('AxBxxCxxxDxxxxE', 'xxx')}文字列リテラルの利用とクォーテーションについて
Functionsタグの利用時以外でも同じですが、EL式の中で文字列リテラルを利用する際は、シングルクォーテーション、ダブルクォーテーションどちらで囲んでも動作します。
但し、他のタグの属性の値としてEL式を利用する場合は、シングルクォーテーションで囲むことが多い(※)ため、文字列リテラルを利用する際は、シングルクォーテーションで囲むように統一することを推奨します。
※属性の値として利用する場合でも、バックスラッシュ(\ ※半角の¥)を用いてエスケープすることで、ダブルクォーテーションで囲むこともできますが、表記が複雑になり誤読を招くため推奨されません。
<%-- そのままHTMLに出力の場合はどちらでも動作可能 --%>
<p>${fn:toUpperCase('abc')}</p>
<p>${fn:toUpperCase("abc")}</p>
<%-- 属性値の中で使う場合はシングルクォーテーションを推奨 --%>
<p><c:out value="${fn:toUpperCase('abc')}"/></p>
<%-- 属性値の中でダブルクォーテーションで囲む場合はエスケープが必要 --%>
<p><c:out value="${fn:toUpperCase(\"abc\")}"/></p>
文字列リテラルの中でシングルクォーテーション、ダブルクォーテーションを利用したい時は、状況に応じてエスケープが必要になります。どちらで囲んでいるかによって、少しだけエスケープの内容が異なります。
①文字列リテラルをシングルクォーテーションで囲んでいる場合
そのままHTMLに出力する場合は、文字列リテラル内のシングルクォーテーションの直前にバックスラッシュを記述してエスケープします。この場合、ダブルクォーテーションはエスケープ不要です。(下記の例1ー1)
タグの属性の中で利用している場合は、シングルクォーテーションは前にバックスラッシュを2個、ダブルクォーテーションはバックスラッシュを1個記述してエスケープします。(下記の例1ー2)
<%-- 例1ー1 --%>
<p>${fn:toUpperCase('single\' double"')}</p>
<%-- 例1ー2 --%>
<p><c:out value="${fn:toUpperCase('single\\' double\"')}"/></p>
②文字列リテラルをダブルクォーテーションで囲んでいる場合
そのままHTMLに出力する場合は、文字列リテラル内のダブルクォーテーションの直前にバックスラッシュを記述してエスケープします。この場合、シングルクォーテーションはエスケープ不要です。(下記の例2ー1)
タグの属性の中で利用している場合は、ダブルクォーテーションは前にバックスラッシュを3個記述してエスケープします。この場合、属性の中でもシングルクォーテーションはエスケープ不要です。(下記の例2ー2)
<%-- 例2ー1 --%>
<p>${fn:toUpperCase("single' double\"")}</p>
<%-- 例2ー2 --%>
<p><c:out value="${fn:toUpperCase(\"single' double\\\"\")}"/></p>
いかがでしたでしょうか。EL式やこれらのタグを組み合わせて利用することで、少々複雑なパターンであっても比較的簡潔なJSPの記述が可能となりますので、まずはこのようなタグがあることだけでも覚えておくと良いでしょう。
次回の記事では、残りのJSTLのタグライブラリのうち、サイトの国際化・多言語対応に利用される i18n(fmt:)タグライブラリについて説明します。

